文本编译工具VIM详解8.2(文本处理工具)
命令模式
命令模式,又称为Normal模式,功能强大,只是此模式输入指令并在屏幕上显示,所以需要记忆大量 的快捷按键才能更好的使用
退出VIM
ZZ 保存退出
ZQ 不保存退出
光标跳转
字符间跳转:
h: 左
L: 右
j: 下
k: 上
#COMMAND:跳转由#指定的个数的字符
单词间跳转:
w:下一个单词的词首
e:当前或下一单词的词尾
b:当前或前一个单词的词首
#COMMAND:由#指定一次跳转的单词数
当前页跳转:
H:页首
M:页中间行
L:页底
zt:将光标所在当前行移到屏幕顶端
zz:将光标所在当前行移到屏幕中间
zb:将光标所在当前行移到屏幕底端
行首行尾跳转:
^ 跳转至行首的第一个非空白字符
0 跳转至行首
$ 跳转至行尾
行间移动:
#G 或者扩展命令模式下
:# 跳转至由第#行
G 最后一行
1G, gg 第一行
句间移动:
) 下一句
( 上一句
段落间移动:
} 下一段
{ 上一段
命令模式翻屏操作
Ctrl+f 向文件尾部翻一屏,相当于Pagedown
Ctrl+b 向文件首部翻一屏,相当于Pageup
Ctrl+d 向文件尾部翻半屏
Ctrl+u 向文件首部翻半屏
字符编辑
x 剪切光标处的字符
#x 剪切光标处起始的#个字符
xp 交换光标所在处的字符及其后面字符的位置
~ 转换大小写
J 删除当前行后的换行符
替换命令(replace)
r 只替换光标所在处的一个字符
R 切换成REPLACE模式(在末行出现-- REPLACE -- 提示),按ESC回到命令模式
删除命令(delete)
准确说是剪切,可p粘贴。
d 删除命令,可结合光标跳转字符,实现范围删除
d$ 删除到行尾
d^ 删除到非空行首
d0 删除到行首
dw 删除到下一个单词的词首
de 删除到下一个单词的词尾
db 删除到当前或前一个单词的词首
#COMMAND
dd: 剪切光标所在的行
#dd 多行删除
D:从当前光标位置一直删除到行尾,等同于d$
复制命令(yank)
y 复制,行为相似于d命令
y$
y0
y^
ye
yw
yb
#COMMAND
yy:复制行
#yy 复制多行
Y:复制整行
粘贴命令(paste)
小p 缓冲区存的如果为整行,则粘贴当前光标所在行的下方;否则,则**粘贴至当前光标所在处的后面**
大P 缓冲区存的如果为整行,则粘贴当前光标所在行的上方;否则,**则粘贴至当前光标所在处的前面**
改变命令(change)
命令 c 删除后切换成插入模式
c$
c^
c0
cb
ce
cw
#COMMAND
cc #删除当前行并输入新内容,相当于S
#cc
C #删除当前光标到行尾,并切换成插入模式,相当于c$
命令模式操作文本总结
| Change (replace) | Delete (cut) | Yank (copy) | |
|---|---|---|---|
| Line | cc | dd | yy |
| Letter | cl | dl | yl |
| Word | cw | dw | yw |
| Sentence ahead | c) | d) | y) |
| Sentence behind | c( | d( | y( |
| Paragraph above | c{ | d{ | y{ |
| Paragraph below | c} | d} | y} |
查找
/PATTERN:从当前光标所在处向文件尾部查找
?PATTERN:从当前光标所在处向文件首部查找
n:与命令同方向
N:与命令反方向
撤消更改
u 撤销最近的更改,相当于windows中ctrl+z
#u 撤销之前多次更改
U 撤消光标落在这行后所有此行的更改
Ctrl-r 重做最后的“撤消”更改,相当于windows中crtl+y
. 重复前一个操作
#. 重复前一个操作#次
高级用法
常见Command:y 复制、d 删除、gU 变大写、gu 变小写
范例:
0y$ 命令
0 → 先到行头
y → 从这里开始拷贝
$ → 拷贝到本行最后一个字符
范例:粘贴“wang”100次
100iwang [ESC]
di" 光标在” “之间,则删除” “之间的内容
yi( 光标在()之间,则复制()之间的内容
vi[ 光标在[]之间,则选中[]之间的内容
dtx 删除字符直到遇见光标之后的第一个 x 字符
ytx 复制字符直到遇见光标之后的第一个 x 字符
可视化模式
在末行有”– VISUAL – “指示,表示在可视化模式
允许选择的文本块
- v 面向字符,– VISUAL –
- V 面向整行,– VISUAL LINE –
- ctrl-v 面向块,– VISUAL BLOCK –
可视化键可用于与移动键结合使用
w ) } 箭头等
突出显示的文字可被删除,复制,变更,过滤,搜索,替换等
范例:在文件指定行的行首插入#
1、先将光标移动到指定的第一行的行首
2、输入ctrl+v 进入可视化模式
3、向下移动光标,选中希望操作的每一行的第一个字符
4、输入大写字母 I 切换至插入模式
5、输入 #
6、按 ESC 键
范例:在指定的块位置插入相同的内容
1、光标定位到要操作的地方
2、CTRL+v 进入“可视块”模式,选取这一列操作多少行
3、SHIFT+i(I)
4、输入要插入的内容
5、按 ESC 键
多文件模式
vim FILE1 FILE2 FILE3 ...
:next 下一个
:prev 前一个
:first 第一个
:last 最后一个
:wall 保存所有
:qall 不保存退出所有
:wqall保存退出所有
多窗口模式
多文件分割
vim -o|-O FILE1 FILE2 ...
-o: 水平或上下分割
-O: 垂直或左右分割(vim only)
在窗口间切换:Ctrl+w, Arrow
单文件窗口分割
Ctrl+w,s:split, 水平分割,上下分屏
Ctrl+w,v:vertical, 垂直分割,左右分屏
ctrl+w,q:取消相邻窗口
ctrl+w,o:取消全部窗口
:wqall 退出
vim 的寄存器
vim 有26个命名寄存器和1个无名寄存器,常存放不同的剪贴板内容,可以不同会话间共享。
寄存器名称:a, b, …, z 格式:"寄存器 放在数字和命令之间。
范例:
3"tyy 表示复制3行到t寄存器中
“tp 表示将t寄存器内容粘贴
未指定,将使用无名寄存器。
有10个数字寄存器,用0, 1, …, 9表示,0存放最近复制内容,1存放最近删除内容。当新的文本变更和删除时,1转存到2,2转存到3,以此类推。数字寄存器不能在不同会话间共享。
标记和宏(macro)
ma 将当前位置标记为a,26个字母均可做标记,mb、mc等等
‘a 跳转到a标记的位置,实用的文档内标记方法,文档中跳跃编辑时很有用
qa 录制宏 a,a 为宏的名称,末行提示recording @a
q 停止录制宏
@a 执行宏 a
@@ 重新执行上次执行的宏
110. 编辑二进制文件
## 以二进制方式打开文件
vim -b binaryfile
## 扩展命令模式下,利用 xxd 命令转换为可读的十六进制
:%!xxd
## 切换至插入模式下,编辑二进制文件
## 切换至扩展命令模式下,利用 xxd 命令转换回二进制
:%!xxd -r
#保存退出
帮助
help
:help topic
Use :q to exit help
#vimtutor
文本常见处理工具
文件内容查看命令
查看文本文件内容
cat
cat 可以查看文本内容
格式:
cat [OPTION]... [FILE]...
常见选项
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
-E:显示行结束符$
-e:相当于 -vE 的组合,显示所有字符,包括不可打印字符,并在每行末尾显示 $ 符号。例如,cat -e file.txt 将显示 file.txt 文件的内容,包括不可打印字符,并在每行末尾显示 $ 符号。
-T:将制表符(Tab)显示为 ^I。例如,cat -T file.txt 将显示 file.txt 文件的内容,并将制表符显示为 ^I。
-A:相当于 -vET 的组合,显示所有控制符
-v:使用 ^ 和 M- 符号显示不可打印字符。例如,cat -v file.txt 将显示 file.txt 文件的内容,并将不可打印字符显示为 ^ 和 M- 符号。
cut -d: -f1 中:
-d: 选项指定了字段分隔符为冒号 :。这意味着 cut 命令会将文本中的每一行根据冒号分隔成多个字段。
-f1 选项指定了要提取的字段编号。在这个例子中,1 表示第一个字段。
因此,cut -d: -f1 命令会将输入文本的每一行根据冒号分隔,并提取每行的第一个字段。
nl
显示行号,相当于cat -b
[root@centos8 ~]#cat /data/f1.txt
a
b
c
d
e
f
g
h
[root@centos8 ~]#nl /data/f1.txt
1 a
2 b
3 c
4 d
5 e
6 f
7 g
8 h
tac
逆向显示文本内容
[root@centos8 ~]#cat /data/fa.txt
1
2
3
4
5
[root@centos8 ~]#tac /data/fa.txt
5
4
3
2
1
[root@centos8 ~]#tac
a
bb
ccc 按ctrl+d
ccc
bb
a
[root@centos8 ~]#seq 10 | tac
10
9
8
7
6
5
4
3
2
1
rev
将同一行的内容逆向显示
[root@centos8 ~]#cat /data/fa.txt
1 2 3 4 5
a b c
[root@centos8 ~]#tac /data/fa.txt
a b c
1 2 3 4 5
[root@centos8 ~]#rev /data/fa.txt
5 4 3 2 1
c b a
[root@centos8 ~]#rev
abcdef
fedcba
[root@centos8 ~]#echo {1..10} |rev
01 9 8 7 6 5 4 3 2 1
查看非文本文件内容
范例:hexdump
hexdump -C -n 512 /dev/sda
00000000 eb 63 90 10 8e d0 bc 00 b0 b8 00 00 8e d8 8e c0 |.c..............|
echo {a..z} | tr -d ' '|hexdump -C
00000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 |abcdefghijklmnop|
00000010 71 72 73 74 75 76 77 78 79 7a 0a |qrstuvwxyz.|
0000001b
分页查看文件内容
可以实现分页查看文件,可以配合管道实现输出信息的分页 格式
more [OPTIONS...] FILE...
选项:
d: 显示翻页及退出提示
q:提前退出
ctrl+d 往回翻页
less
less 也可以实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
比more更好,有less就不用more
查看时有用的命令包括:
文本 搜索 文本
n/N 跳到下一个 或 上一个匹配
显示文本前面或后面的行内容
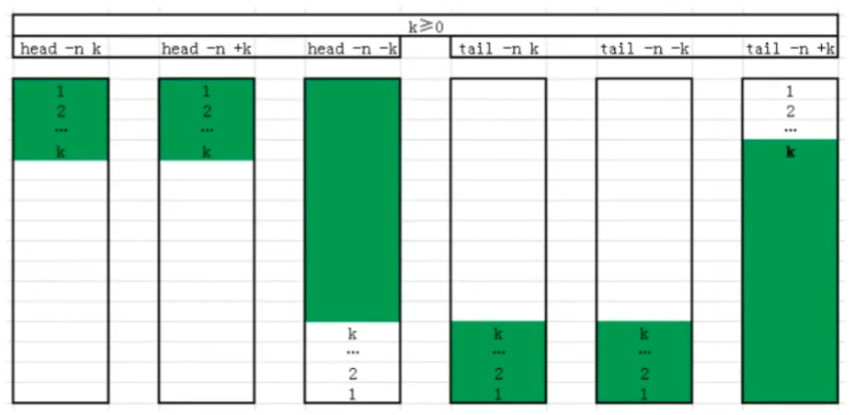
head
可以显示文件或标准输入的前面行(默认10) 格式:
head [OPTION]... [FILE]...
选项:
-c, --bytes [大小]:指定输出的字节数。例如,head -c 1024 file.txt 将输出文件的前1024个字节。
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前,例如,head -n 5 file.txt 将输出文件的前5行。
-# 同上
-q, --quiet, --silent:不显示文件名标题当有多于一个文件时要处理。
-v, --verbose:总是显示文件名标题当有多于一个文件时要处理。
范例:
[root@centos8 ~]#head -n 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@centos8 ~]#head -3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@centos8 ~]#echo a我b | head -c4
a我[root@centos8 ~]#
[root@centos8 ~]#cat /dev/urandom | tr -dc '[:alnum:]'| head -c10
G755MlZatW[root@centos8 ~]#cat /dev/urandom | tr -dc '[:alnum:]'| head -c10
ASsax6DeBz[root@centos8 ~]#cat /dev/urandom | tr -dc '[:alnum:]'| head -c10 |
tee pass.txt | passwd --stdin mage
Changing password for user mage.
passwd: all authentication tokens updated successfully.
[root@centos8 ~]#cat pass.txt
AGT952Essg[root@centos8 ~]#su - wang
[wang@centos8 ~]$su - mage
Password:
[root@centos8 ~]#cat seq.log
1
2
3
4
5
6
7
8
9
10
[root@centos8 ~]#head -n 3 seq.log
1
2
3
[root@centos8 ~]#head -n -3 seq.log
1
2
3
4
5
6
7
[root@centos8 ~]#head -n +3 seq.log
1
2
3
tail
tail 和head 相反,查看文件或标准输入的倒数行(默认后10)
格式:
ail [OPTION]... [FILE]...
常用选项
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-q, --quiet, --silent:不显示文件名标题当有多于一个文件时要处理。
-f 跟踪显示文件fd新追加的内容,常用日志监控,这个选项通常用于监控日志文件的实时更新。相当于 --follow=descriptor,当文件删除再新
建同名文件,将无法继续跟踪文件。
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文
件
--pid=PID:与 -f 选项一起使用,当指定的进程ID(PID)结束时,停止跟踪文件。
-v, --verbose:总是显示文件名标题当有多于一个文件时要处理。
tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8已经无此工具
范例:
[root@centos8 ~]#cat /data/f1.txt
1
2
3
4
5
6
7
8
9
10
[root@centos8 ~]#tail -n 3 /data/f1.txt
8
9
10
[root@centos8 ~]#tail -n +3 /data/f1.txt
3
4
5
6
7
8
9
10
范例(只显示第二行):
[root@centos8 ~]#tail -3 /var/log/messages
Dec 20 09:49:01 centos8 dbus-daemon[952]: [system] Successfully activated
service 'net.reactivated.Fprint'
Dec 20 09:49:01 centos8 systemd[1]: Started Fingerprint Authentication Daemon.
Dec 20 09:49:13 centos8 su[6887]: (to mage) root on pts/0
#实时查看日志
[root@centos8 ~]#tail -f /var/log/messages
Dec 20 08:36:40 centos8 systemd[1321]: Startup finished in 52ms.
Dec 20 08:36:40 centos8 systemd[1]: Started User Manager for UID 0.
Dec 20 08:47:01 centos8 systemd[1]: Starting dnf makecache...
Dec 20 08:47:02 centos8 dnf[1465]: AppStream
213 kB/s | 4.3 kB 00:00
Dec 20 08:47:02 centos8 dnf[1465]: BaseOS
163 kB/s | 3.9 kB 00:00
Dec 20 08:47:04 centos8 dnf[1465]: EPEL
2.6 kB/s | 5.3 kB 00:02
Dec 20 08:47:09 centos8 dnf[1465]: EPEL
884 kB/s | 4.3 MB 00:05
Dec 20 08:47:12 centos8 dnf[1465]: extras
727 B/s | 1.5 kB 00:02
Dec 20 08:47:12 centos8 dnf[1465]: Metadata cache created.
Dec 20 08:47:12 centos8 systemd[1]: Started dnf makecache.
#只查看最新发生的日志
[root@centos8 ~]#tail -fn0 /var/log/messages
[root@centos8 ~]#tail -0f /var/log/messages
#取IP行
[root@centos8 data]#ifconfig | head -2 | tail -1
│
inet 10.0.0.8 netmask 255.255.255.0 broadcast 10.0.0.255
或者
[root@centos8 data]#ifconfig | tall-n -2 | head -n1
范例: 显示第6行
[root@centos8 ~]#seq 20| head -n 6|tail -n1
6
[root@centos8 ~]#seq 20| tail -n +6 |head -n1
6
head 和 tail 总结
按列抽取文本 cut
cut 命令可以提取文本文件或STDIN数据的指定列
格式
cut [OPTION]... [FILE]..
常用选项
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
范例:
[root@centos8 ~]#cut -d: -f1,3-4,7 /etc/passwd
[root@centos8 ~]#ifconfig |head -n2 |tail -n1|cut -d" " -f10
10.0.0.8
[root@centos8 ~]#ifconfig |head -n2 |tail -n1|tr -s " " |cut -d " " -f3
10.0.0.8
[root@centos8 ~]#df | tr -s ' '|cut -d' ' -f5 |tr -dc "[0-9\n]"
0
0
1
0
5
1
15
1
[root@centos8 ~]#df | tr -s ' ' % |cut -d% -f5 |tr -d '[:alpha:]'
0
0
1
0
5
1
15
1
[root@centos8 ~]#df | cut -c44-46 |tr -d '[:alpha:]'
0
0
1
0
5
1
15
1
[root@centos8 ~]#cut -d: -f1,3,7 --output-delimiter="---" /etc/passwd
root---0---/bin/bash
bin---1---/sbin/nologin
daemon---2---/sbin/nologin
cat /etc/passwd | cut -d: -f7
cut -c2-5 /usr/share/dict/words
[root@centos8 ~]#echo {1..10}| cut -d ' ' -f1-10 --output-delimiter="+" |bc
55
范例: 取分区利用率
[root@centos8 ~]#df|tr -s ' ' |cut -d' ' -f5 |tr -d %
[root@centos8 ~]#df|tr -s ' ' '%'|cut -d% -f5
Use
0
0
2
0
3
1
15
0
100
[root@centos8 ~]#df |cut -c 44-46|tail -n +2
0
0
3
0
3
1
13
0
[root@centos8 ~]#df | tail -n +2|tr -s ' ' % |cut -d% -f5
0
0
1
0
3
1
19
0
100
[root@centos8 ~]#df | tail -n +2|tr -s ' ' |cut -d' ' -f5 |tr -d %
0
0
1
0
3
1
19
0
100
合并多个文件 paste
paste 合并多个文件同行号的列到一行
格式
paste [OPTION]... [FILE]...
常用选项:
-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
范例:
[root@centos8 ~]#cat alpha.log
a
b
c
d
e
f
g
h
[root@centos8 ~]#cat seq.log
1
2
3
4
5
[root@centos8 ~]#cat alpha.log seq.log
a
b
c
d
e
f
g
h
1
2
3
4
5
[root@centos8 ~]#paste alpha.log seq.log
a 1
b 2
c 3
d 4
e 5
f
g
h
[root@centos8 ~]#paste -d":" alpha.log seq.log
a:1
b:2
c:3
d:4
e:5
f:
g:
h:
[root@centos8 ~]#paste -s seq.log
1 2 3 4 5
[root@centos8 ~]#paste -s alpha.log
a b c d e f g h
[root@centos8 ~]#paste -s alpha.log seq.log
a b c d e f g h
1 2 3 4 5
[root@centos8 ~]#cat title.txt
ceo
coo
cto
[root@centos8 ~]#cat emp.txt
mage
zhang
wang
xu
[root@centos8 ~]#paste title.txt emp.txt
ceo mage
coo zhang
cto wang
xu
[root@centos8 ~]#paste -s title.txt emp.txt
ceo coo cto
mage zhang wang xu
[root@centos8 ~]#paste -s -d: f1.log f2.log
1:2:3:4:5:6:7:8:9:10
a:b:c:d:e:f:g:h:i:j
[root@centos8 ~]#seq 10
1
2
3
4
5
6
7
8
9
10
[root@centos8 ~]#seq 10 |paste -s -d+|bc
55
范例: 批量修改密码
[root@centos8 ~]#cat user.txt
wang
mage
[root@centos8 ~]#cat pass.txt
123456
magedu
[root@centos8 ~]#paste -d: user.txt pass.txt
wang:123456
mage:magedu
[root@centos8 ~]#paste -d: user.txt pass.txt|chpasswd
分析文本的工具
文本数据统计:wc
整理文本:sort
比较文件:diff和patch
收集文本统计数据 wc (word count)
wc 命令可用于统计文件的行总数、单词总数、字节总数和字符总数
可以对文件或STDIN中的数据统计
常用选项
-c:统计字符数。例如,wc -c file.txt 将输出 file.txt 文件中的字符数。
-m:统计字符数,与 -c 类似,但是 -m 会计算多字节字符(在UTF-8等编码中)为单个字符。例如,wc -m file.txt 将输出 file.txt 文件中的字符数,多字节字符算作一个字符。
-w:统计单词数。例如,wc -w file.txt 将输出 file.txt 文件中的单词数。在 wc 中,单词被定义为由空白字符(空格、制表符、换行符等)分隔的字符串。
-L:输出最长行的长度。例如,wc -L file.txt 将输出 file.txt 文件中最长一行的字符数。
-l:统计行数。例如,wc -l file.txt 将输出 file.txt 文件中的行数。
-h:当与 -c、-m 或 -w 选项一起使用时,以人类可读的格式(如K、M、G)显示大小。例如,wc -ch file.txt 将以字节为单位并以K、M、G的形式显示 file.txt 文件的字符数。
这些选项可以单独使用,也可以组合使用,以实现不同的统计需求。例如,wc -lwc file.txt 将同时输出 file.txt 文件的行数、单词数和字符数。
范例:
wc story.txt
39 237 1901 story.txt
行数 单词数 字节数
[root@centos8 ~]#ll title.txt
-rw-r--r-- 1 root root 30 Dec 20 11:05 title.txt
[root@centos8 ~]#cat title1.txt
ceo mage
coo zhang
cto wang
[root@centos8 ~]#wc title.txt
3 6 30 title.txt
[root@centos8 ~]#wc -l title.txt 只显示行
3 title.txt
[root@centos8 ~]#cat title.txt | wc -l 显示行但不显示文件名
3
文本排序 sort
把整理过的文本显示在STDOUT,不改变原始文件
格式:
sort [options] file(s)
常用选项
-u 选项(独特,unique),合并重复项,即去重
-r 执行反方向(由上至下)整理。例如,sort -r file.txt 将按降序输出 file.txt 的内容。
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-t 指定字段分隔符。例如,sort -t ':' -k 3 /etc/passwd 将按第三个由冒号分隔的字段排序 /etc/passwd 文件。
-k 指定排序的关键字。例如,sort -k 2 file.txt 将按第二列的值排序。
-o:将输出写入到文件中,而不是标准输出。例如,sort -o sorted.txt file.txt 将排序后的内容写入到 sorted.txt 文件中。
-b:忽略每行开头的空白字符。例如,sort -b file.txt 将在排序时忽略每行开头的空白字符。
-M:按月份排序。例如,sort -M file.txt 将按月份顺序排序,其中月份名称应使用三位缩写形式(如Jan、Feb等)。
这些选项可以组合使用,以实现更复杂的排序需求。例如,sort -t ‘:’ -k 3 -n -r /etc/passwd 将按第三个由冒号分隔的字段(UID)的数字值降序排序 /etc/passwd 文件。
范例:
[root@centos8 data]#cut -d: -f1,3 /etc/passwd|sort -t: -k2 -nr |head -n3
nobody:65534
xiaoming:1002
mage:1001
#统计日志访问量
[root@centos8 data]#cut -d" " -f1 /var/log/nginx/access_log |sort -u|wc -l
201
范例:统计分区利用率
[root@centos8 ~]#df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 391676 0 391676 0% /dev
tmpfs 408092 0 408092 0% /dev/shm
tmpfs 408092 5816 402276 2% /run
tmpfs 408092 0 408092 0% /sys/fs/cgroup
/dev/sda2 104806400 2259416 102546984 3% /
/dev/sda3 52403200 398608 52004592 1% /data
/dev/sda1 999320 130848 799660 15% /boot
tmpfs 81616 0 81616 0% /run/user/0
/dev/sr0 7377866 7377866 0 100% /misc/cd
#查看分区利用率最高值
[root@centos8 ~]#df| tr -s ' ' '%'|cut -d% -f5|sort -nr|head -1
100
[root@centos8 ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort
0
0
0
1
1
1
15
5
[root@centos8 ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -n
0
0
0
1
1
1
5
15
[root@centos8 ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -n |tail
-n1
15
[root@centos8 ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -nr
15
5
1
1
1
0
0
0
[root@centos8 ~]#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -nr|head
-n1
15
面试题:有两个文件,a.txt与b.txt ,合并两个文件,并输出时确保每个数字也唯一
#a.txt中的每一个数字在本文件唯一
200
100
34556
23
...
#b.txt中的每一个数字在本文件唯一
123
43
200
3321
...
#就是将两个文件合并后重复的行去除,不保留
100
345563
123
43
3321
...
去重 uniq
uniq命令从输入中删除前后相接的重复的行
格式:
uniq [OPTION]... [FILE]...
常见选项:
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
uniq常和sort 命令一起配合使用:
范例:
sort userlist.txt | uniq -c
范例:统计日志访问量最多的请求
[root@centos8 data]#cut -d" " -f1 access_log |sort |uniq -c|sort -nr |head -3
4870 172.20.116.228
3429 172.20.116.208
2834 172.20.0.222
[root@centos8 data]#lastb -f btmp-34 | tr -s ' ' |cut -d ' ' -f3|sort |uniq -c
|sort -nr | head -3
86294 58.218.92.37
43148 58.218.92.26
18036 112.85.42.201
范例:并发连接最多的远程主机IP
[root@centos8 ~]#ss -nt|tail -n+2 |tr -s ' ' : |cut -d: -f6|sort|uniq -c|sort -
nr |head -n2
7 10.0.0.1
2 10.0.0.7
范例:取两个文件的相同和不同的行
[root@centos8 data]#cat test1.txt
a
b
1
c
[root@centos8 data]#cat test2.txt
b
e
f
c
1
2
#取文件的共同行
[root@centos8 data]#cat test1.txt test2.txt | sort |uniq -d
1
b
c
#取文件的不同行
[root@centos8 data]#cat test1.txt test2.txt | sort |uniq -u
2
a
e
f
比较文件
diff
diff 命令比较两个文件之间的区别
-u 选项来输出“统一的(unified)”diff格式文件,最适用于补丁文件
范例:
[root@centos8 ~]#cat f1.txt
mage
zhang
wang
xu
[root@centos8 ~]#cat f2.txt
magedu
zhang sir
wang
xu
shi
[root@centos8 ~]#diff f1.txt f2.txt
1,2c1,2
< mage
< zhang
---
> magedu
> zhang sir
4a5
> shi
[root@centos8 ~]#diff -u f1.txt f2.txt
--- f1.txt 2019-12-13 21:31:30.892775671 +0800
+++ f2.txt 2019-12-13 22:00:14.373677728 +0800
@@ -1,4 +1,5 @@
-mage
-zhang
+magedu
+zhang sir
wang
xu
+shi
[root@centos8 ~]#diff -u f1.txt f2.txt > f.patch
[root@centos8 ~]#rm -f f2.txt
[root@centos8 ~]#patch -b f1.txt f.patch (恢复f2并备份f1,因为恢复后f2内容覆盖f1。)
patching file f1.txt
[root@centos8 ~]#cat f1.txt
magedu
zhang sir
wang
xu
shi
[root@centos8 ~]#cat f1.txt.orig
mage
zhang
wang
xu
patch
patch 复制在其它文件中进行的改变(要谨慎使用
-b 选项来自动备份改变了的文件
范例:
diff -u foo.conf foo2.conf > foo.patch
patch -b foo.conf foo.patch
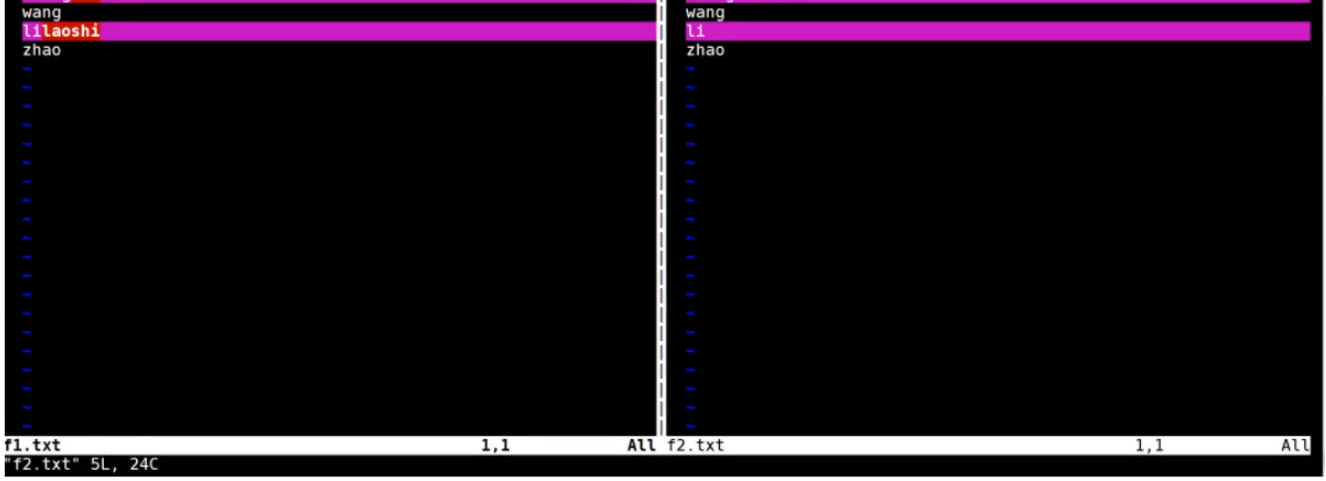
vimdiff
相当于 vim -d
[root@centos8 ~]#cat f1.txt
mage
zhangsir
wang
lilaoshi
zhao
[root@centos8 ~]#cat f2.txt
mage
zhang
wang
li
zhao
[root@centos8 ~]#which vimdiff
/usr/bin/vimdiff
[root@centos8 ~]#ll /usr/bin/vimdiff
lrwxrwxrwx. 1 root root 3 Nov 12 2019 /usr/bin/vimdiff -> vim
[root@centos8 ~]#vimdiff f1.txt f2.txt
cmp
范例:查看二进制文件的不同
[root@centos8 data]#ll /usr/bin/dir /usr/bin/ls
-rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/dir
-rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/ls
[root@centos8 data]#ll /usr/bin/dir /usr/bin/ls -i
201839444 -rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/dir
201839465 -rwxr-xr-x. 1 root root 166448 May 12 2019 /usr/bin/ls
[root@centos8 data]#diff /usr/bin/dir /usr/bin/ls
Binary files /usr/bin/dir and /usr/bin/ls differ
[root@centos8 ~]#cmp /bin/dir /bin/ls
/bin/dir /bin/ls differ: byte 737, line 2
#跳过前735个字节,观察后面30个字节
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/ls
000002df 00 05 6d da 3f 1b 77 91 91 63 a7 de 55 63 a2 b9 |..m.?.w..c..Uc..|
000002ef d9 d2 45 55 4c 00 00 00 00 03 00 00 00 7d |..EUL........}|
000002fd
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/dir
000002df 00 f1 21 4e f2 19 7e ef 38 0d 9b 3e d7 54 08 39 |..!N..~.8..>.T.9|
000002ef e4 74 4d 69 25 00 00 00 00 03 00 00 00 7d |.tMi%........}|
000002fd
总结
 练习
1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址
练习
1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址
2、查出分区空间使用率的最大百分比值
3、查出用户UID最大值的用户名、UID及shell类型
4、查出/tmp的权限,以数字方式显示
5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序