正则表达式和相关工具及文件查找压缩
正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)
不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符。
正则表达式被很多程序和开发语言所广泛支持:vim, less,grep,sed,awk, nginx,mysql 等
正则表达式分两类:
基本正则表达式:BRE Basic Regular Expressions
扩展正则表达式:ERE Extended Regular Expressions
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块,如:PCRE(Perl Compatible Regular
Expressions)
正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组
帮助:man 7 regex
基本正则表达式元字符
字符匹配
. 匹配任意单个字符(除了\n),可以是一个汉字或其它国家的文字 正则表达式.配的是文本中的字符串 通配符*匹配文件名的字符串
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符,示例:[^wang]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围
广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
-----------------
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。注意 Unicode
正则表达式会匹配全角空格符
\S #匹配任何非空白字符。等价于 [^\f\r\t\v]
\w #匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[_[:alnum:]字]
\W #匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[^_[:alnum:]字]
范例:
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6]'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6].'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@centos8 ~]#ls /etc/ | grep 'rc[.0-6]\.'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* #任意长度的任意字符
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
范例:
[root@centos8 ~]#cat test.txt
google
goooooooooooooooooogle
ggle
gogle
gooooOOOOO00000gle
gooogle
[root@centos8 ~]#grep 'go\{2,\}gle' test.txt
google
goooooooooooooooooogle
gooogle
[root@centos8 ~]#grep 'goo\+gle' test.txt
google
goooooooooooooooooogle
gooogle
[root@centos8 ~]#grep 'goo*gle' test.txt
google
goooooooooooooooooogle
gogle
gooogle
[root@centos8 ~]#grep 'gooo*gle' test.txt
google
goooooooooooooooooogle
gooogle
范例: 匹配正负数
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep '-\?[0-9]\+'
grep: invalid option -- '\'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep '\-\?[0-9]\+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '-?[0-9]+'
grep: invalid option -- '?'
Usage: grep [OPTION]... PATTERN [FILE]...
Try 'grep --help' for more information.
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '\-?[0-9]+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E -- '-?[0-9]+'
-1 -2 123 -123 234
[root@centos8 ~]#echo -1 -2 123 -123 234 |grep -E '(-)?[0-9]+'
-1 -2 123 -123 234
范例: 取IP地址
[root@rocky9 ~]# ifconfig ens160
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.0.0.131 netmask 255.255.255.0 broadcast 10.0.0.255
inet6 fe80::20c:29ff:fe0f:3d9d prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:0f:3d:9d txqueuelen 1000 (Ethernet)
RX packets 1770 bytes 158243 (154.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2849 bytes 335686 (327.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
位置锚定
位置锚定可以用于定位出现的位置
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行
^$ #空行
^[[:space:]]*$ #空白行
\< 或 \b #词首锚定,用于单词模式的左侧
\> 或 \b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词
#注意: 单词是由字母,数字,下划线组成
范例:
[root@centos8 ~]#grep '^[^#]' /etc/fstab
UUID=acf9bd1f-caae-4e28-87be-e53afec61347 / xfs
defaults 0 0
UUID=1770b87e-db5a-445e-bff1-1653ac64b3d6 /boot ext4
defaults 1 2
UUID=ffffd919-d674-44d9-a4e7-402874f0a1f0 /data xfs
defaults 0 0
UUID=409e36d2-ac5e-423f-ad78-9b12db4576bd swap swap
defaults 0 0
范例:排除掉空行和#开头的行
[root@centos8 ~]#grep -v '^$' /etc/profile|grep -v '^#'
[root@centos8 ~]#grep '^[^#]' /etc/profile
[root@centos8 ~]#grep -v '^$\|#' /etc/profile
[root@rocky9 etc]# echo root | grep '\<root'
root
[root@rocky9 etc]# echo rooter | grep '\<root'
rooter
[root@rocky9 etc]# echo -rooter | grep '\<root'
-rooter
[root@rocky9 etc]# echo aaaroot | grep 'root\>'
aaaroot
[root@rocky9 etc]# echo -root: | grep '\root\>'
-root:
[root@rocky9 etc]# df |grep '^/dev' |grep -o ' *[0-9]\{1,3\}%'
3%
32%
1%
分组其它
分组
分组:() 将多个字符捆绑在一起,当作一个整体处理.如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, …
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
注意: \0 表示正则表达式匹配的所有字符
示例:
[root@rocky9 etc]# echo ooo | grep 'o\{3\}'
ooo
[root@rocky9 etc]# echo oooo | grep 'o\{3\}'
oooo
[root@rocky9 etc]# echo abcabcabc | grep 'abc\{3\}'
[root@rocky9 etc]# echo abcabcabccc | grep 'abc\{3\}'
abcabcabccc
[root@rocky9 etc]# echo abcabcabc | grep '\(abc\)\{3\}'
abcabcabc
\(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
注意: ‘后向引用’ 引用前面的分组括号中的模式所匹配字符,而非模式本身.s
或者
或者:|
示例:
a\|b #a或b
C\|cat #C或cat
\(C\|c\)at #Cat或cat
范例:排除空行和#开头的行
[root@centos6 ~]#grep -v '^#' /etc/httpd/conf/httpd.conf |grep -v ^$
[root@centos6 ~]#grep -v '^#\|^$' /etc/httpd/conf/httpd.conf
[root@centos6 ~]#grep -v '^\(#\|$\)' /etc/httpd/conf/httpd.conf
[root@centos6 ~]#grep "^[^#]" /etc/httpd/conf/httpd.conf
正则表达式练习
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
2、显示/etc/passwd文件中不以/bin/bash结尾的行
3、显示用户rpc默认的shell程序
4、找出/etc/passwd中的两位或三位数
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
7、显示CentOS7上所有UID小于1000以内的用户名和UID
8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户
名和shell同名的行
9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
扩展正则表达式元字符
字符匹配
. 任意单个字符
[wang] 指定范围的字符
[^wang] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
次数匹配
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
位置锚定
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
分组其它
() 分组
后向引用:\1, \2, ... 注意: \0 表示正则表达式匹配的所有字符
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
范例:
[root@centos8 ~]#ifconfig | grep -Ewo "(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-
5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])"|head -n1
10.0.0.8
扩展正则表达式练习
1、显示三个用户root、mage、wang的UID和默认shell
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
4、使用egrep取出上面路径的目录名
5、统计last命令中以root登录的每个主机IP地址登录次数
6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
7、显示ifconfig命令结果中所有IPv4地址
8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
文件查找
在文件系统上查找符合条件的文件
文件查找:
非实时查找(数据库查找):locate
实时查找:find
locate
- locate 查询系统上预建的文件索引数据库 /var/lib/mlocate/mlocate.db
- 索引的构建是在系统较为空闲时自动进行(周期性任务),执行updatedb可以更新数据库
- 索引构建过程需要遍历整个根文件系统,很消耗资源
- locate和updatedb命令来自于mlocate包 工作特点:
- 查找速度快
- 模糊查找
- 非实时查找
- 搜索的是文件的全路径,不仅仅是文件名
- 可能只搜索用户具备读取和执行权限的目录 格式:
locate [OPTION]... [PATTERN]...
常用选项
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目
-r 使用基本正则表达式
范例:
#搜索名称或路径中包含“conf"的文件
locate conf
#使用Regex来搜索以“.conf"结尾的文件
locate -r '\.conf$'
## 更新locate数据库
updatedb
范例: locatedb创建数据库
[root@centos8 ~]#dnf -y install mlocate
[root@centos8 ~]#locate conf
locate: can not stat () `/var/lib/mlocate/mlocate.db': No such file or directory
[root@centos8 ~]#updatedb
[root@centos8 ~]#ll /var/lib/mlocate/mlocate.db
-rw-r----- 1 root slocate 1041065 Jun 11 20:08 /var/lib/mlocate/mlocate.db
[root@centos8 ~]#locate -n 3 conf
/boot/config-4.18.0-147.el8.x86_64
/boot/grub2/i386-pc/configfile.mod
/boot/loader/entries/5b85fc7444b240a992c42ce2a9f65db5-0-rescue.conf
范例: 文件新创建和删除,无法马上更新locate数据库
[root@centos8 ~]#touch test.log
[root@centos8 ~]#locate test.log
locate: can not stat () `/var/lib/mlocate/mlocate.db': No such file or directory
[root@centos8 ~]#updatedb
[root@centos8 ~]#locate test.log
/root/test.log
[root@centos8 ~]#touch test2.log
[root@centos8 ~]#locate test2.log
[root@centos8 ~]#updatedb
[root@centos8 ~]#locate test2.log
/root/test2.log
[root@centos8 ~]#rm -f test2.log
[root@centos8 ~]#locate test2.log
/root/test2.log
范例:
[root@centos8 ~]#locate -n 10 -ir '\.CONF$'
/boot/loader/entries/5b85fc7444b240a992c42ce2a9f65db5-0-rescue.conf
/boot/loader/entries/5b85fc7444b240a992c42ce2a9f65db5-4.18.0-147.el8.x86_64.conf
/etc/autofs.conf
/etc/autofs_ldap_auth.conf
/etc/dracut.conf
/etc/fuse.conf
/etc/host.conf
/etc/idmapd.conf
/etc/kdump.conf
/etc/krb5.conf
find
find 是实时查找工具,通过遍历指定路径完成文件查找
工作特点:
- 查找速度略慢
- 精确查找
- 实时查找
- 查找条件丰富
- 可能只搜索用户具备读取和执行权限的目录 格式:
find [OPTION]... [查找路径] [查找条件] [处理动作]
查找路径:指定具体目标路径;默认为当前目录
查找条件:指定的查找标准,可以文件名、大小、类型、权限等标准进行;默认为找出指定路径下的所
有文件
处理动作:对符合条件的文件做操作,默认输出至屏幕
常见选项:
-name:按照文件名查找文件。
-type:按照文件类型查找文件,如f(普通文件)、d(目录)、l(符号链接)等。
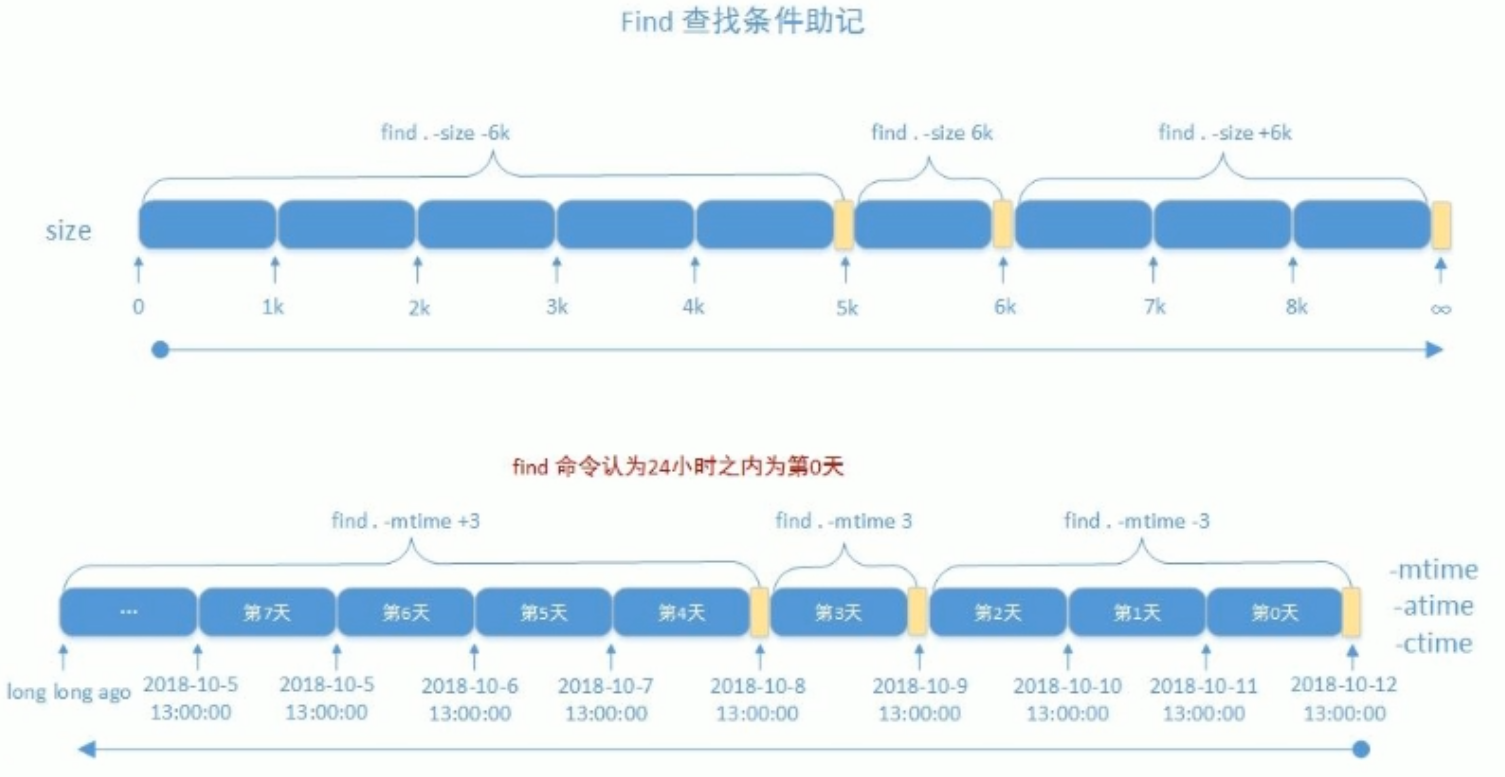
-size:按照文件大小查找文件,可以使用c(字节)、k(千字节)、M(兆字节)等单位。
-mtime:按照文件最后修改时间查找文件,后面跟天数。
-atime:按照文件最后访问时间查找文件,后面跟天数。
-ctime:按照文件状态改变时间查找文件,后面跟天数。
-perm:按照文件权限查找文件。
-user:按照文件所有者查找文件。
-group:按照文件所属组查找文件。
-exec:对找到的文件执行指定的命令。
-ok:与-exec类似,但在执行命令前会询问用户。
-print:默认选项,打印找到的文件路径。
-delete:删除找到的文件。
-empty:查找空文件或目录。
-path:按照路径模式查找文件。
-regex:按照正则表达式查找文件名。
这些选项可以组合使用,以实现更复杂的搜索条件。例如,要查找过去7天内被修改过的所有普通文件,可以使用以下命令:
bash find /path/to/search -type f -mtime -7
指定搜索目录层级
-maxdepth level 最大搜索目录深度,指定目录下的文件为第1级
-mindepth level 最小搜索目录深度
范例:
find /etc -maxdepth 2 -mindepth 2
对每个目录先处理目录内的文件,再处理目录本身
-depth
-d #warning: the -d option is deprecated; please use -depth instead, because the
latter is a POSIX-compliant feature
范例:
[root@centos8 data]#tree /data/test
/data/test
├── f1.txt
├── f2.txt
└── test2
└── test3
├── f3.txt
└── f4.txt
4 directories, 2 files
[root@centos8 data]#find /data/test
/data/test
/data/test/f1.txt
/data/test/f2.txt
/data/test/test2
/data/test/test2/test3
/data/test/test2/test3/f3.txt
/data/test/test2/test3/f4.txt
[root@centos8 data]#find /data/test -depth
/data/test/f1.txt
/data/test/f2.txt
/data/test/test2/test3/f3.txt
/data/test/test2/test3/f4.txt
/data/test/test2/test3
/data/test/test2
/data/test
根据文件名和inode查找
-name "文件名称" #支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来
-iname "文件名称" #不区分字母大小写
-inum n #按inode号查找
-samefile name #相同inode号的文件
-links n #链接数为n的文件
-regex “PATTERN" #以PATTERN匹配整个文件路径,而非文件名称
范例:
find -name snow.png
find -iname snow.png
find / -name ".txt"
find /var –name "log*"
[root@centos8 data]#find -regex ".*\.txt$"
./scripts/b.txt
./f1.txt
根据属主、属组查找
-user USERNAME #查找属主为指定用户(UID)的文件
-group GRPNAME #查找属组为指定组(GID)的文件
-uid UserID #查找属主为指定的UID号的文件
-gid GroupID #查找属组为指定的GID号的文件
-nouser #查找没有属主的文件
-nogroup #查找没有属组的文件
根据文件类型查找
-type TYPE
TYPE可以是以下形式:
f: 普通文件
d: 目录文件
l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
p: 管道文件
范例:
#查看/home的目录
find /home –type d -ls
空文件或目录
-empty
范例:
[root@centos8 ~]#find /app -type d -empty
组合条件
与:-a ,默认多个条件是与关系,所以可以省略-a
或:-o
非:-not !
范例:
[root@centos8 ~]#find /etc/ -type d -o -type l |wc -l
307
[root@centos8 ~]#find /etc/ -type d -o -type l -ls |wc -l
101
[root@centos8 ~]#find /etc/ \( -type d -o -type l \) -ls |wc -l
307
德·摩根定律:
- (非 A) 且 (非 B) = 非(A 或 B)
- (非 A) 或 (非 B) = 非(A 且 B) 示例:
!A -a !B = !(A -o B)
!A -o !B = !(A -a B)
范例:
find -user joe -group joe
find -user joe -not -group joe
find -user joe -o -user jane
find -not \( -user joe -o -user jane \)
find / -user joe -o -uid 500
范例:
[root@centos8 data]#find ! \( -type d -a -empty \)| wc -l
56
[root@centos8 data]#find ! -type d -o ! -empty |wc -l
56
[mage@centos8 data]$find ! -user wang ! -user mage
.
./script40
./script40/backup
./script40/backup/args.sh
./script40/backup/chook_rabbit.sh
./script40/backup/disk_check.sh
./script40/backup/ping.sh
./script40/backup/systeminfo.sh
./script40/backup/test_read.sh
./script40/backup/test.sh
./script40/if_bmi.sh
./script40/case_yesorno.sh
./script40/case_yesorno2.sh
./script40/b.txt
./f1.txt
./test
./test/f1.txt.link
./f1.txtlink
./test2
[root@centos8 home]#ll
total 0
drwx------. 2 mage mage 62 Jan 16 17:53 mage
drwx------. 2 wang wang 62 Jan 16 10:43 wang
drwx------ 2 xiaoming xiaoming 62 Apr 6 09:51 xiaoming
[root@centos8 home]#find ! \( -user wang -o -user mage \)
.
./xiaoming
./xiaoming/.bash_logout
./xiaoming/.bash_profile
./xiaoming/.bashrc
[root@centos8 home]#find ! -user wang -a ! -user mage
.
./xiaoming
./xiaoming/.bash_logout
./xiaoming/.bash_profile
./xiaoming/.bashrc
#找出/tmp目录下,属主不是root,且文件名不以f开头的文件
find /tmp \( -not -user root -a -not -name 'f*' \) -ls
find /tmp -not \( -user root -o -name 'f*' \) –ls
排除目录
范例:
#查找/etc/下,除/etc/security目录的其它所有.conf后缀的文件
find /etc -path '/etc/security' -a -prune -o -name "*.conf"
#查找/etc/下,除/etc/security和/etc/systemd,/etc/dbus-1三个目录的所有.conf后缀的文件
find /etc \( -path "/etc/security" -o -path "/etc/systemd" -o -path "/etc/dbus-
1" \) -a -prune -o -name "*.conf"
#排除/proc和/sys目录
find / \( -path "/sys" -o -path "/proc" \) -a -prune -o -type f -a -mmin -1
根据文件大小来查找
-size [+|-]#UNIT #常用单位:k, M, G,c(byte),注意大小写敏感
#UNIT: #表示(#-1, #],如:6k 表示(5k,6k]
-#UNIT #表示[0,#-1],如:-6k 表示[0,5k]
+#UNIT #表示(#,∞),如:+6k 表示(6k,∞)
范例:
find / -size +10G
[root@centos8 ~]#find / -size +10G
/proc/kcore
find: ‘/proc/25229/task/25229/fd/6’: No such file or directory
find: ‘/proc/25229/task/25229/fdinfo/6’: No such file or directory
find: ‘/proc/25229/fd/5’: No such file or directory
find: ‘/proc/25229/fdinfo/5’: No such file or directory
[root@centos8 ~]#ll -h /proc/kcore
-r-------- 1 root root 128T Dec 14 2020 /proc/kcore
[root@centos8 ~]#du -sh /proc/kcore
0 /proc/kcore
根据时间戳
#以“天"为单位
-atime [+|-]#
# #表示[#,#+1) 10表示[10-11)
+# #表示[#+1,∞] 10表示[11,∞]
-# #表示[0,#) 10表示[0-10)
-mtime
-ctime
#以“分钟"为单位
-amin
-mmin
-cmin
根据权限查找
-perm [/|-]MODE
MODE #精确权限匹配
/MODE #任何一类(u,g,o)对象的权限中只要有一位匹配即可,或关系,+ 从CentOS 7开始淘汰
-MODE #每一类对象都必须同时拥有指定权限,与关系
0 表示不关注
说明:
find -perm 755 会匹配权限模式恰好是755的文件
只要当任意人有写权限时,find -perm /222就会匹配
只有当每个人都有写权限时,find -perm -222才会匹配
只有当其它人(other)有写权限时,find -perm -002才会匹配
只有当任意人没有执行权限时,find /etc/ -type f ! -perm -111 -ls才会匹配 并显示权限。
正则表达式
-regextype type
Changes the regular expression syntax understood by -regex and -iregex tests
which occur later on the command line. Currently-implemented types are
emacs (this is the default), posix-awk, posix-basic, posix-egrep and posix-
extended.
-regex pattern
File name matches regular expression pattern. This is a match on the whole
path, not a search. For example, to match a file named `./fubar3', you can
use the regular expression `.*bar.' or `.*b.*3', but not `f.*r3'. The regular
expressions understood by find are by default Emacs Regular Expressions, but
this can be changed with the -regextype option.
范例:
find /you/find/dir -regextype posix-extended -regex "regex"
处理动作
-print:默认的处理动作,显示至屏幕
-ls:类似于对查找到的文件执行"ls -dils"命令格式输出
-fls file:查找到的所有文件的长格式信息保存至指定文件中,相当于 -ls > file
-delete:删除查找到的文件,慎用!
-ok COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令,对于每个文件执行命令之前,都会
交互式要求用户确认
-exec COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令
{}: 用于引用查找到的文件名称自身
关于 {} ;
https://askubuntu.com/questions/339015/what-does-mean-in-the-find-command
范例:
#备份配置文件,添加.orig这个扩展名
find -name ".conf" -exec cp {} {}.orig \;
#提示删除存在时间超过3天以上的joe的临时文件
find /tmp -ctime +3 -user joe -ok rm {} \;
#在主目录中寻找可被其它用户写入的文件
find ~ -perm -002 -exec chmod o-w {} \;
#查找/data下的权限为644,后缀为sh的普通文件,增加执行权限
find /data –type f -perm 644 -name "*.sh" –exec chmod 755 {} \;
#查找所有文件名以.conf结尾的文件,为每个找到的文件执行后面的命令之前提示用户确认。用户需要输入y来确认操作,或者输入n来跳过当前文件的操作。这个分号是find命令的命令结束符。反斜杠\用于转义分号,因为在shell中,分号通常用作命令分隔符。在这里,转义分号告诉shell,分号是find命令的一部分,而不是shell脚本的命令分隔符。
[root@rocky8 ~]# find -name "*.conf" -ok mv {} /data/ \;
< mv ... /a.conf > ? y
[root@rocky8~]#ls /data
a.conf
参数替换 xargs
由于很多命令不支持管道|来传递参数,xargs用于产生某个命令的参数,xargs 可以读入 stdin 的数
据,并且以空格符或回车符将 stdin 的数据分隔成为参数
另外,许多命令不能接受过多参数,命令执行可能会失败,xargs 可以解决
注意:文件名或者是其他意义的名词内含有空格符的情况
find 经常和 xargs 命令进行组合,形式如下:
find | xargs COMMAND
常见选项:
-0, --null:输入项以 null 字符结尾,而不是空白字符,通常与 find -print0 或 sort -z 等命令结合使用。
-a file, --arg-file=file:从文件中读取输入项而不是标准输入。
-d delimiter, --delimiter=delimiter:指定输入项的分隔符,默认是空白字符。
-E eof-str, --eof[=eof-str]:如果输入中包含指定的字符串,则停止读取。
-e [eof-str], --eof[=eof-str]:与 -E 相同,但更兼容 POSIX。
-I replace-str, --replace[=replace-str]:替换字符串,默认是 {},用于在命令行中使用输入项。
-i, --replace:与 -I 相同,但默认使用 {} 作为替换字符串。
-L max-lines, --max-lines=max-lines:指定最大行数,每行最多包含一个输入项。
-l[max-lines], --max-lines[=max-lines]:与 -L 相同,但更兼容 POSIX。
-n max-args, --max-args=max-args:指定命令行上每个命令的最大参数数量。
-P max-procs, --max-procs=max-procs:指定并行执行的最大进程数。
-p, --interactive:在执行每个命令之前提示用户确认。
-r, --no-run-if-empty:如果输入为空,不运行命令。
-s max-chars, --max-chars=max-chars:指定命令行的最大字符数。
-t, --verbose:在执行命令之前打印命令到标准错误。
-x, --exit:如果输入的长度超过了最大命令行长度,停止执行。
范例::
#显示10个数字
[root@centos8 ~]#seq 10 | xargs
1 2 3 4 5 6 7 8 9 10
#删除当前目录下的大量文件
ls | xargs rm
#
find -name "*.sh" | xargs ls -Sl
[root@centos8 data]#echo {1..10} |xargs
1 2 3 4 5 6 7 8 9 10
[root@centos8 data]#echo {1..10} |xargs -n1
1
2
3
4
5
6
7
8
9
10
[root@centos8 data]#echo {1..10} |xargs -n2
1 2
3 4
5 6
7 8
9 10
#批量创建和删除用户
echo user{1..10} |xargs -n1 useradd
echo user{1..100} | xargs -n1 userdel -r
#这个命令是错误的
find /sbin/ -perm /700 | ls -l
#查找有特殊权限的文件,并排序
find /bin/ -perm /7000 | xargs ls -Sl
#此命令和上面有何区别?
find /bin/ -perm -7000 | xargs ls -Sl
#以字符nul分隔
find -type f -name "*.txt" -print0 | xargs -0 rm
#并发执行多个进程
seq 100 |xargs -i -P10 wget -P /data http://10.0.0.8/{}.html
#并行下载bilibili视频
yum install python3-pip -y
pip3 install you-get
seq 60 | xargs -i -P3 you-get https://www.bilibili.com/video/BV14K411W7UF?p={}
命令解释:
seq 10: 这个命令生成一个从1到10的数字序列。这些数字将被用作后续命令的输入。
xargs -i -P10: xargs命令通常用于从标准输入中读取数据,并将其作为参数传递给另一个命令。在这个命令中:
-i选项告诉xargs使用{}作为输入行的占位符。
-P10选项指定xargs可以同时运行10个进程,这样可以并行下载文件,提高效率。
wget -P /data http://10.0.0.8/{}.html: 这是xargs将执行的命令。wget是一个用于下载文件的命令行工具。在这个命令中:
-P /data选项指定下载的文件应该保存到/data目录。
http://10.0.0.8/{}.html是文件的URL。由于使用了-i选项,xargs会用来自seq 10的数字替换{},从而生成一系列的URL,例如http://10.0.0.8/1.html,http://10.0.0.8/2.html,依此类推,直到http://10.0.0.8/10.html。
练习
1、查找/var目录下属主为root,且属组为mail的所有文件
2、查找/var目录下不属于root、lp、gdm的所有文件
3、查找/var目录下最近一周内其内容修改过,同时属主不为root,也不是postfix的文件
4、查找当前系统上没有属主或属组,且最近一个周内曾被访问过的文件
5、查找/etc目录下大于1M且类型为普通文件的所有文件
6、查找/etc目录下所有用户都没有写权限的文件
7、查找/etc目录下至少有一类用户没有执行权限的文件
8、查找/etc/init.d目录下,所有用户都有执行权限,且其它用户有写权限的文件
压缩和解压缩
主要针对单个文件压缩,而非目录
compress 和 uncompress
此工具来自于ncompress包,此工具目前已经很少使用
对应的文件是 .Z 后缀
格式
compress Options [file ...]
uncompress file.Z
常用选项
-d 解压缩,相当于uncompress
-c 结果输出至标准输出,不删除原文件
-v 显示详情
zcat file.Z 不显式解压缩的前提下查看文本文件内容 范例:
zcat file.Z >file
gzip和gunzip
来自于 gzip 包
对应的文件是 .gz 后缀
格式:
gzip [OPTION]... FILE ...
常用选项:
-k keep, 保留原文件,CentOS 8 新特性
-d 解压缩,相当于gunzip
-c 结果输出至标准输出,保留原文件不改变
-# 指定压缩比,#取值为1-9,值越大压缩比越大
范例:
#解压缩
gunzip file.gz
#不显式解压缩的前提下查看文本文件内容
zcat file.gz
范例:
gzip -c messages >messages.gz
gzip -c -d messages.gz > messages
zcat messages.gz > messages
cat messages | gzip > m.gz
bzip2和bunzip2
来自于 bzip2 包 对应的文件是 .bz2 后缀 格式:
bzip2 [OPTION]... FILE ...
常用选项
-k keep, 保留原文件
-d 解压缩
-c 结果输出至标准输出,保留原文件不改变
-# 1-9,压缩比,默认为9
范例:
bunzip2 file.bz2 解压缩
bzcat file.bz2 不显式解压缩的前提下查看文本文件内容
xz 和 unxz
来自于 xz 包
对应的文件是 .xz 后缀
格式
xz [OPTION]... FILE ...
常用选项
-k keep, 保留原文件
-d 解压缩
-c 结果输出至标准输出,保留原文件不改变
-# 压缩比,取值1-9,默认为6
范例:
unxz file.xz #解压缩
xzcat file.xz #不显式解压缩的前提下查看文本文件内容
zip 和 unzip
zip 可以实现打包目录和多个文件成一个文件并压缩,但可能会丢失文件属性信息,如:所有者和组信
息,一般建议使用 tar 代替
分别来自于 zip 和 unzip 包
对应的文件是 .zip 后缀
范例: zip帮助
[root@centos8 ~]#zip
Copyright (c) 1990-2008 Info-ZIP - Type 'zip "-L"' for software license.
Zip 3.0 (July 5th 2008). Usage:
zip [-options] [-b path] [-t mmddyyyy] [-n suffixes] [zipfile list] [-xi list]
The default action is to add or replace zipfile entries from list, which
can include the special name - to compress standard input.
If zipfile and list are omitted, zip compresses stdin to stdout.
-f freshen: only changed files -u update: only changed or new files
-d delete entries in zipfile -m move into zipfile (delete OS files)
-r recurse into directories -j junk (don't record) directory names
-0 store only -l convert LF to CR LF (-ll CR LF to LF)
-1 compress faster -9 compress better
-q quiet operation -v verbose operation/print version info
-c add one-line comments -z add zipfile comment
-@ read names from stdin -o make zipfile as old as latest entry
-x exclude the following names -i include only the following names
-F fix zipfile (-FF try harder) -D do not add directory entries
-A adjust self-extracting exe -J junk zipfile prefix (unzipsfx)
-T test zipfile integrity -X eXclude eXtra file attributes
-y store symbolic links as the link instead of the referenced file
-e encrypt -n don't compress these suffixes
-h2 show more help
[root@centos8 ~]#zip -h2
Extended Help for Zip
See the Zip Manual for more detailed help
Zip stores files in zip archives. The default action is to add or replace
zipfile entries.
Basic command line:
zip options archive_name file file ...
Some examples:
Add file.txt to z.zip (create z if needed): zip z file.txt
Zip all files in current dir: zip z *
Zip files in current dir and subdirs also: zip -r z .
范例:
#打包并压缩
zip -r /backup/sysconfig.zip /etc/sysconfig/
#不包括目录本身,只打包目录内的文件和子目录
cd /etc/sysconfig; zip -r /root/sysconfig.zip *
#默认解压缩至当前目录
unzip /backup/sysconfig.zip
#解压缩至指定目录,如果指定目录不存在,会在其父目录(必须事先存在)下自动生成
unzip /backup/sysconfig.zip -d /tmp/config
cat /var/log/messages | zip messages -
#-p 表示管道
unzip -p message.zip > message
加密和解密
范例: 交互式加密和解密
[root@centos8 magedu]#zip -e magedu.zip *
Enter password:
Verify password:
adding: ca.crt (deflated 25%)
adding: client.ovpn (deflated 27%)
adding: dh.pem (deflated 19%)
adding: magedu.crt (deflated 45%)
adding: magedu.key (deflated 24%)
adding: magedu.tar (deflated 72%)
adding: ta.key (deflated 40%)
[root@centos8 magedu]#mv magedu.zip /root
[root@centos8 magedu]#cd
[root@centos8 ~]#unzip magedu.zip
Archive: magedu.zip
[magedu.zip] ca.crt password:
password incorrect--reenter: [root@centos8 ~]#
[root@centos8 ~]#unzip magedu.zip
Archive: magedu.zip
[magedu.zip] ca.crt password:
inflating: ca.crt
inflating: client.ovpn
inflating: dh.pem
inflating: magedu.crt
inflating: magedu.key
inflating: magedu.tar
inflating: ta.key
范例: 非交互式加密和解密
[root@centos8 test]#zip -P 123456 magedu.zip *
adding: ca.crt (deflated 25%)
adding: client.ovpn (deflated 27%)
adding: dh.pem (deflated 19%)
adding: ta.key (deflated 40%)
[root@centos8 test]#mv magedu.zip /opt
[root@centos8 test]#cd /opt
[root@centos8 opt]#unzip -P 123456 magedu.zip
Archive: magedu.zip
[magedu.zip] ca.crt password:
inflating: ca.crt
inflating: client.ovpn
inflating: dh.pem
inflating: ta.key
打包和解包
tar
tar 即 Tape ARchive 磁带归档,可以对目录和多个文件打包一个文件,并且可以压缩,保留文件属性不
丢失,常用于备份功能,推荐使用
对应的文件是 .tar 后缀
格式
tar [-ABcdgGhiklmMoOpPrRsStuUvwWxzZ][-b <区块数目>][-C <目的目录>][-f <备份文件>][-F
<Script文件>][-K <文件>][-L <媒体容量>][-N <日期时间>][-T <范本文件>][-V <卷册名称>][-X
<范本文件>][-<设备编号><存储密度>][--after-date=<日期时间>][--atime-preserve][--
backuup=<备份方式>][--checkpoint][--concatenate][--confirmation][--delete][--
exclude=<范本样式>][--force-local][--group=<群组名称>][--help][--ignore-failed-
read][--new-volume-script=<Script文件>][--newer-mtime][--no-recursion][--null][--
numeric-owner][--owner=<用户名称>][--posix][--erve][--preserve-order][--preserve-
permissions][--record-size=<区块数目>][--recursive-unlink][--remove-files][--rsh-
command=<执行指令>][--same-owner][--suffix=<备份字尾字符串>][--totals][--use-
compress-program=<执行指令>][--version][--volno-file=<编号文件>][文件或目录...]
选项:
-A或--catenate 新增文件到已存在的备份文件。
-b<区块数目>或--blocking-factor=<区块数目> 设置每笔记录的区块数目,每个区块大小为12Bytes。
-B或--read-full-records 读取数据时重设区块大小。
-c或--create 建立新的备份文件。
-C<目的目录>或--directory=<目的目录> 切换到指定的目录。
-d或--diff或--compare 对比备份文件内和文件系统上的文件的差异。
-f<备份文件>或--file=<备份文件> 指定备份文件。
-F<Script文件>或--info-script=<Script文件> 每次更换磁带时,就执行指定的Script文件。
-g或--listed-incremental 处理GNU格式的大量备份。
-G或--incremental 处理旧的GNU格式的大量备份。
-h或--dereference 不建立符号连接,直接复制该连接所指向的原始文件。
-i或--ignore-zeros 忽略备份文件中的0 Byte区块,也就是EOF。
-k或--keep-old-files 解开备份文件时,不覆盖已有的文件。
-K<文件>或--starting-file=<文件> 从指定的文件开始还原。
-l或--one-file-system 复制的文件或目录存放的文件系统,必须与tar指令执行时所处的文件系统相
同,否则不予复制。
-L<媒体容量>或-tape-length=<媒体容量> 设置存放每体的容量,单位以1024 Bytes计算。
-m或--modification-time 还原文件时,不变更文件的更改时间。
-M或--multi-volume 在建立,还原备份文件或列出其中的内容时,采用多卷册模式。
-N<日期格式>或--newer=<日期时间> 只将较指定日期更新的文件保存到备份文件里。
-o或--old-archive或--portability 将资料写入备份文件时使用V7格式。
-O或--stdout 把从备份文件里还原的文件输出到标准输出设备。
-p或--same-permissions 用原来的文件权限还原文件。
-P或--absolute-names 文件名使用绝对名称,不移除文件名称前的"/"号。
-r或--append 新增文件到已存在的备份文件的结尾部分。
-R或--block-number 列出每个信息在备份文件中的区块编号。
-s或--same-order 还原文件的顺序和备份文件内的存放顺序相同。
-S或--sparse 倘若一个文件内含大量的连续0字节,则将此文件存成稀疏文件。
-t或--list 列出备份文件的内容。
-T<范本文件>或--files-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让tar解开或
建立符合设置条件的文件。
-u或--update 仅置换较备份文件内的文件更新的文件。
-U或--unlink-first 解开压缩文件还原文件之前,先解除文件的连接。
-v或--verbose 显示指令执行过程。
-V<卷册名称>或--label=<卷册名称> 建立使用指定的卷册名称的备份文件。
-w或--interactive 遭遇问题时先询问用户。
-W或--verify 写入备份文件后,确认文件正确无误。
-x或--extract或--get 从备份文件中还原文件。
-X<范本文件>或--exclude-from=<范本文件> 指定范本文件,其内含有一个或多个范本样式,让ar排除
符合设置条件的文件。
-z或--gzip或--ungzip 通过gzip指令处理备份文件。
-Z或--compress或--uncompress 通过compress指令处理备份文件。
-<设备编号><存储密度> 设置备份用的外围设备编号及存放数据的密度。
--after-date=<日期时间> 此参数的效果和指定"-N"参数相同。
--atime-preserve 不变更文件的存取时间。
--backup=<备份方式>或--backup 移除文件前先进行备份。
--checkpoint 读取备份文件时列出目录名称。
--concatenate 此参数的效果和指定"-A"参数相同。
--confirmation 此参数的效果和指定"-w"参数相同。
--delete 从备份文件中删除指定的文件。
--exclude=<范本样式> 排除符合范本样式的文件。
--group=<群组名称> 把加入设备文件中的文件的所属群组设成指定的群组。
--help 在线帮助。
--ignore-failed-read 忽略数据读取错误,不中断程序的执行。
--new-volume-script=<Script文件> 此参数的效果和指定"-F"参数相同。
--newer-mtime 只保存更改过的文件。
--no-recursion 不做递归处理,也就是指定目录下的所有文件及子目录不予处理。
--null 从null设备读取文件名称。
--numeric-owner 以用户识别码及群组识别码取代用户名称和群组名称。
--owner=<用户名称> 把加入备份文件中的文件的拥有者设成指定的用户。
--posix 将数据写入备份文件时使用POSIX格式。
--preserve 此参数的效果和指定"-ps"参数相同。
--preserve-order 此参数的效果和指定"-A"参数相同。
--preserve-permissions 此参数的效果和指定"-p"参数相同。
--record-size=<区块数目> 此参数的效果和指定"-b"参数相同。
--recursive-unlink 解开压缩文件还原目录之前,先解除整个目录下所有文件的连接。
--remove-files 文件加入备份文件后,就将其删除。
--rsh-command=<执行指令> 设置要在远端主机上执行的指令,以取代rsh指令。
--same-owner 尝试以相同的文件拥有者还原文件。
--suffix=<备份字尾字符串> 移除文件前先行备份。
--totals 备份文件建立后,列出文件大小。
--use-compress-program=<执行指令> 通过指定的指令处理备份文件。
--version 显示版本信息。
--volno-file=<编号文件> 使用指定文件内的编号取代预设的卷册编号。
(1) 创建归档,保留权限
tar -cpvf /PATH/FILE.tar FILE...
(2) 追加文件至归档: 注:不支持对压缩文件追加
tar -rf /PATH/FILE.tar FILE...
(3) 查看归档文件中的文件列表
tar -t -f /PATH/FILE.tar
(4) 展开归档
tar xf /PATH/FILE.tar
tar xf /PATH/FILE.tar -C /PATH/
(5) 结合压缩工具实现:归档并压缩
-z 相当于gzip压缩工具
-j 相当于bzip2压缩工具
-J 相当于xz压缩工具
范例:
[root@centos8 ~]#tar zcvf etc.tar.gz /etc/
[root@centos8 ~]#tar jcvf etc.tar.bz2 /etc/
[root@centos8 ~]#tar Jcvf etc.tar.xz /etc/
[root@centos8 ~]#ll etc.tar.*
-rw-r--r-- 1 root root 3645926 Dec 20 22:00 etc.tar.bz2
-rw-r--r-- 1 root root 5105347 Dec 20 21:59 etc.tar.gz
-rw-r--r-- 1 root root 3101616 Dec 20 22:00 etc.tar.xz
#利用 tar 进行文件复制
[root@centos8 ~]#tar c /data/ | tar x -C /backup
tar: Removing leading `/' from member names
--exclude 排除文件
范例: 只打包目录内的文件,不所括目录本身
#方法1
[root@centos8 ~]#cd /etc
[root@centos8 etc]#tar zcvf /root/etc.tar.gz ./
#方法2
[root@centos8 ~]#tar -C /etc -zcf etc.tar.gz ./
范例:
tar zcvf /root/a.tgz --exclude=/app/host1 --exclude=/app/host2 /app
-T 选项指定输入文件-X 选项指定包含要排除的文件列表
范例:
tar zcvf mybackup.tgz -T /root/includefilelist -X /root/excludefilelist
split
split 命令可以分割一个文件为多个文件
范例:
#分割大的 tar 文件为多份小文件
split -b Size –d tar-file-name prefix-name
示例:
split -b 1M mybackup.tgz mybackup-parts
#切换成的多个小分文件使用数字后缀
split -b 1M –d mybackup.tgz mybackup-parts
将多个切割的小文件合并成一个大文件
cat mybackup-parts* > mybackup.tar.gz
报告文件系统磁盘使用情况
du命令是Linux和Unix系统中用于报告文件系统磁盘使用情况的工具。-sh是du命令的一些选项,它们的含义如下:
- -s(或–summarize):这个选项告诉du命令只显示每个参数的总计大小,而不是每个子目录的大小。当您对一个目录使用du命令时,它会默认列出该目录及其所有子目录的大小。使用-s选项,您将只看到该目录的总大小。
- -h(或–human-readable):这个选项使得du命令以更易于阅读的格式显示大小,例如1K、234M、2G等,而不是以原始字节为单位。这有助于用户快速理解文件或目录的大小。
因此,du -sh命令的用途是显示指定文件或目录的总大小,并以人类可读的格式(如K、M、G)呈现。
例如,如果您想查看/home/user目录的总大小,您可以执行:
du -sh --exclude='*.git'
常见选项:
-h或--human-readable:以更易于阅读的格式显示大小(例如,1K、234M、2G)。
-s或--summarize:只显示总计的大小,而不列出每个子目录的大小。
-a或--all:列出所有个别文件和目录的磁盘使用情况,而不仅仅是子目录的总计。
-c或--total:显示所有列出的文件和目录的总计大小。
-d或--max-depth:指定目录层次的深度。
--exclude:排除某些文件或目录。
-l或--count-links:如果是硬链接,则重复计算其大小。
-B或--block-size:指定块大小,用于计算磁盘使用情况。
-S或--separate-dirs:不包括子目录的大小。
--apparent-size:显示文件的实际大小,而不是磁盘占用量。
--si:使用1000而不是1024作为大小单位的基础。
要查看当前目录及其子目录中所有文件和目录的磁盘使用情况,并显示总计,可以使用:
du -ach
要查看特定目录的磁盘使用情况,并排除某些类型的文件,例如.git目录,可以使用:
du -sh --exclude='*.git'